🔥 Highlight
- 🔥 Text-Grounded Trajectories is a video generation approach that makes multiple named trajectories you draw on a white canvas into a realistic video
- 🔥 TGT-Wan2.1 and TGT-Wan2.2 model will be publicly available on hugging face.
- 🔥 Our code will be released.
Abstract
We introduce Text-Grounded Trajectories (TGT), a novel framework designed to solve a critical limitation in text-to-video generation: the lack of precise control over multi-objects/scene composition. Our method provides this missing layer of control through an intuitive process of pairing motion paths (trajectories) with localized text descriptions. This allows a user to define both what an object is, and the exact path it should follow through the scene. This technique is particularly powerful in complex, multi-object scenarios, ensuring each entity maintains its unique appearance while adhering to its designated motion script. The result is a state-of-the-art system that generates videos with higher visual quality, more accurate entity alignment, and more precise motion controllability compared to all previous approaches.
Method Overview
To achieve precise control, our method introduces a lightweight plug-in module, Location-Aware Cross-Attention (LACA), which works together with a dual-CFG strategy. This design allows for disentangled control over both the motion and appearance of subjects and remains fully compatible with large-scale pretrained video generation models. To power this architecture, we also designed the first data collection pipeline that automatically extracts paired trajectory-text supervision directly from raw videos. This pipeline provides the missing data necessary to ground local text descriptions in specific motion paths, enabling our model to learn generating video with specified object's identity and its movement.
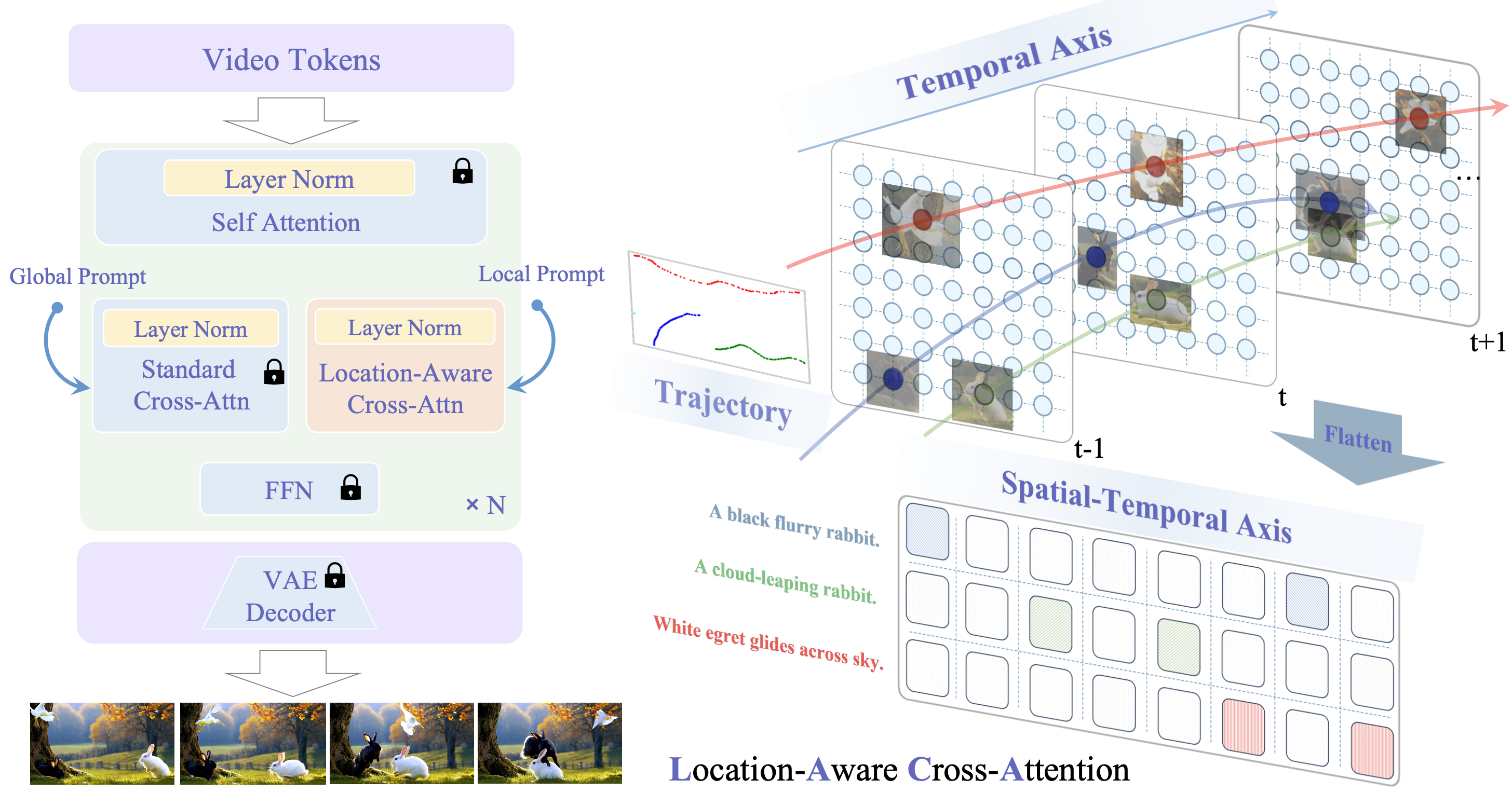
Pipeline of TGT. We propose Location-Aware Cross-Attention (LACA), a cross-attention that injects entity and location information into every DiT block. LACA performs masked attention, ensuring each visual token attends only to its corresponding local text token.
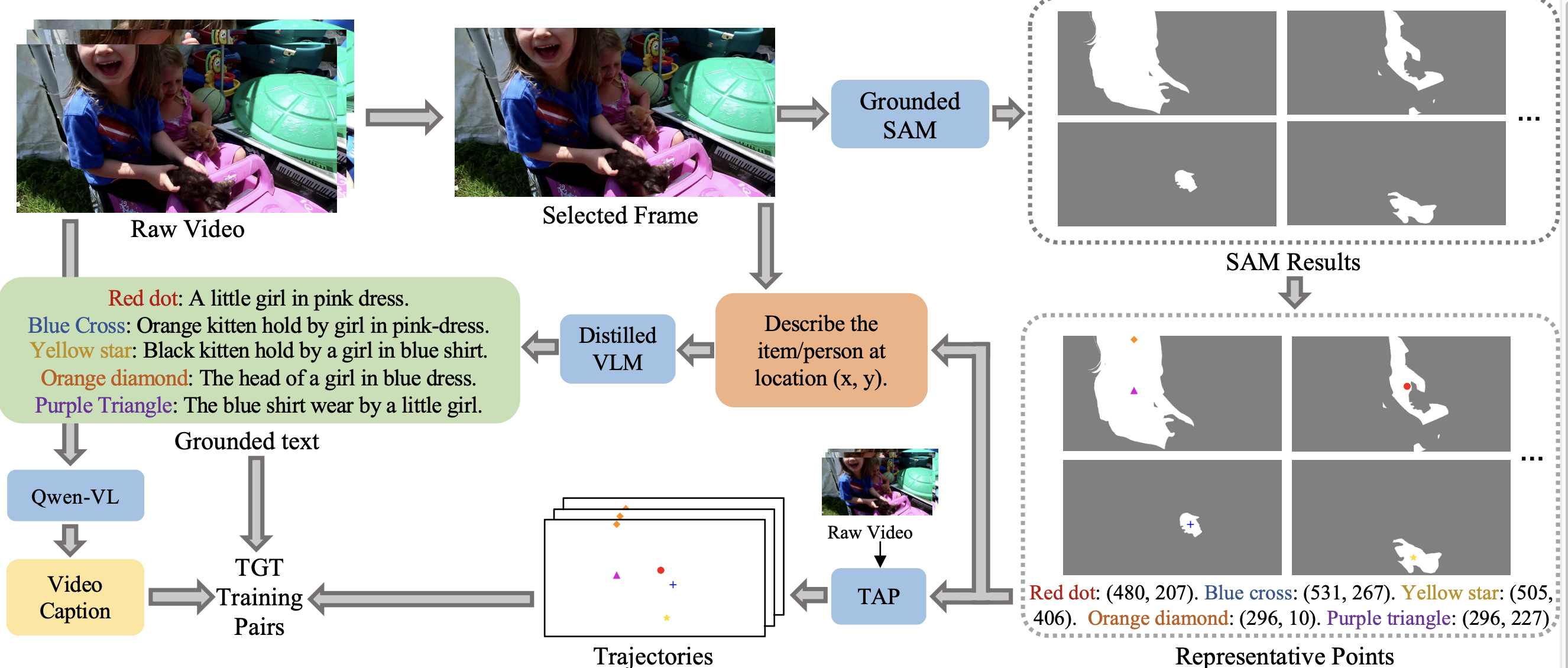
TGT data collection pipeline. We first apply Grounded SAM to segment entities and select representative points. These points are then passed to a point tracker and a distilled VLM to extract trajectories and localized captions, yielding paired trajectory-text supervision.
Input Any Trajectory Instruction
We will provide tools for user to draw trajectories on white canvas and to input text associated with each trajectory. This will come out together with our model for user to try their own examples.
Wan2.1 based TGT results
Wan2.2 based TGT results
Currently under progress
TGT for Video-to-Video applications
TGT can mirror a video by extracting dense text-trajectories pairs from the video then regenerate it. Moreover, by changing entity name in local and global text, TGT enables "video-editing" power.
| Reference Video (for Extracting Motion) | Mirrored Video | Edited Video |
|---|---|---|